
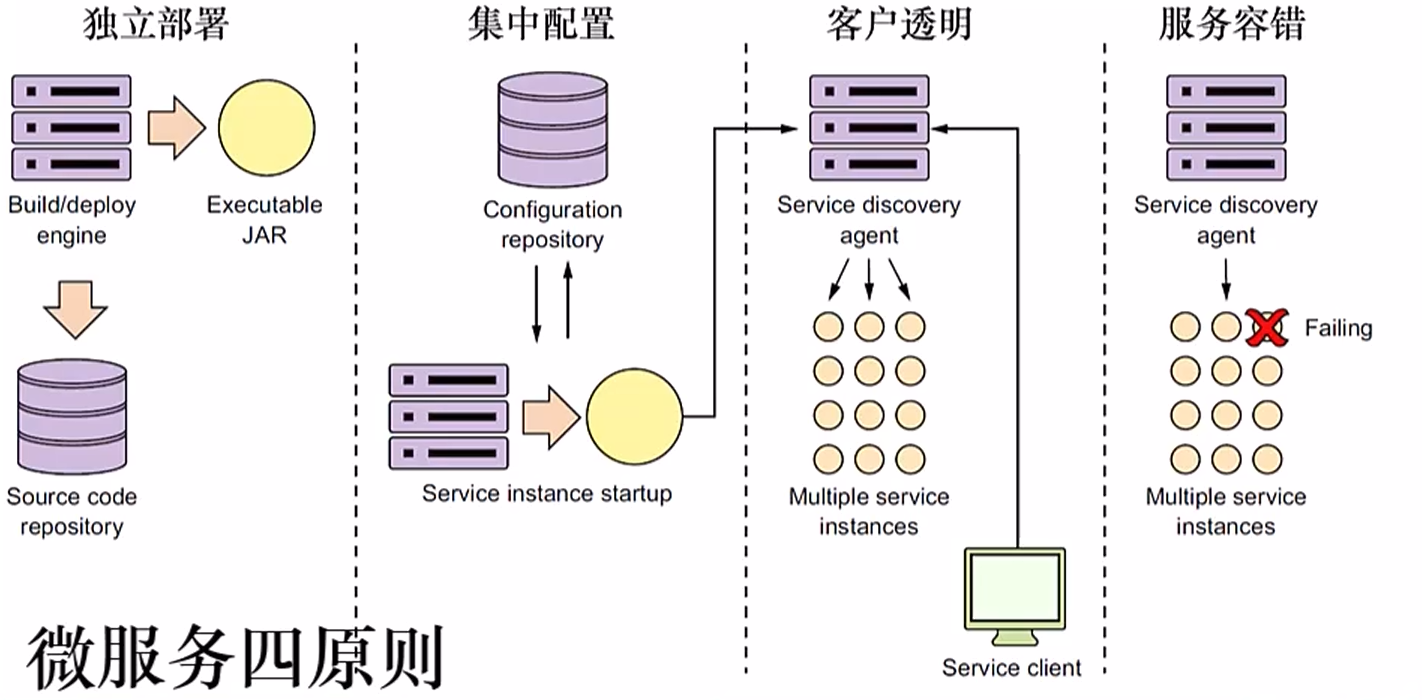
微服务四大设计原则
独立部署
每个微服务都应该能够独立部署、升级和扩展,而不影响其他微服务的正常运行。独立部署使得微服务架构能够灵活应对变化,无论是业务需求变化、性能优化,还是技术更新,都能以最小的代价进行。
- 减少系统间的依赖:一个微服务的更新或部署不会影响到其他服务,避免了传统单体应用中常见的“大规模部署”问题。
- 更高的开发和运维效率:可以根据需求,独立迭代、测试和发布某个微服务。
- 弹性扩展:某些高负载的微服务可以独立扩展,其他微服务不受影响。
比如,在一个电商系统中,订单服务和支付服务是两个微服务。当订单服务的某个功能需要更新时,可以单独更新订单服务而不影响支付服务的正常运行。
集中配置
微服务架构中,所有微服务的配置应该集中管理。配置管理工具(如 nacos 或 eureka)可以帮助我们集中管理和动态更新多个微服务的配置,而无需分别修改每个微服务的配置文件。如果不进行集中配置,当我们修改某个微服务的配置文件时,就需要对该微服务进行重新打包部署,非常繁琐。
- 统一管理:避免每个微服务有独立配置文件,造成分散管理的复杂性。
- 快速更新:可以集中更新所有服务的配置,而无需重新部署每个服务。
- 灵活性和一致性:不同环境(开发、测试、生产)可以共享配置管理,确保配置的一致性。
客户透明
客户(客户端)与微服务之间的交互应该尽量透明,客户端不应关注微服务的内部实现和部署细节。对于微服务来说,不同微服务之间会存在相互调用,而调用的方式并不会通过微服务所在的服务器 ip 去发送请求,而是通过一个查名服务器来集中管理所有服务器 ip 。这样就能使得不同微服务之间直接通过服务名称进行调用。
- 简化客户端开发:客户端只需要调用暴露的 API,不关心服务的具体实现或是否有多个服务在背后处理请求。
- 提升用户体验:即使微服务背后发生了变更,客户端与服务的通信方式保持一致,用户感知不到系统的变动。
- 更好的扩展性和灵活性:服务可以随着需求变化进行重构或扩展,客户端无需做任何更改。
服务容错
微服务架构应该能够容忍部分服务的故障,避免单个微服务的故障引发整个系统崩溃。通过采取容错策略(如熔断器、重试机制、回退策略等),即使某个服务出现问题,系统的其余部分也能继续正常工作。
- 增强系统可靠性:服务容错使得系统能够在部分服务失败的情况下继续正常运行,避免级联故障。
- 提高用户体验:即使某个微服务出现故障,系统仍能返回合适的错误信息或提供降级服务,不至于让用户体验到大规模的中断。
- 容忍服务的不可预测性:在分布式系统中,网络延迟、服务崩溃等都是常见问题,容错机制有助于减轻这些问题带来的影响。
Nacos
Nacos(全称:Dynamic Naming and Configuration Service)是一个开源的 动态服务发现、配置管理 和 服务管理 平台,主要用于分布式系统中微服务架构的服务治理。简单来说,Nacos 解决了微服务架构中服务注册、发现、配置管理等问题。
在一个微服务架构中,服务通常是分布式的,服务的实例可能会动态变化(比如启动、关闭或重启),而每个服务也可能会有不同的配置(如数据库连接、API 配置等)。如何管理这些动态变化的服务和配置,就成了一个挑战。Nacos 就是为了解决这些问题而出现的。
主要功能:
- 服务注册与发现
- 微服务架构中,多个微服务需要相互通信。Nacos 提供了服务注册与发现功能,每个微服务启动时会把自己的信息(如 IP、端口等)注册到 Nacos 上,其他微服务可以通过 Nacos 来查找并调用它。
- 这样,如果某个微服务的实例发生变化(如重新启动或增加新的实例),Nacos 会自动更新,避免了硬编码和手动维护服务地址。
- 动态配置管理
- Nacos 允许集中管理微服务的配置信息(如数据库连接、日志级别等)。你可以将配置文件统一保存在 Nacos 上,微服务启动时从 Nacos 获取配置信息(如果 Nacos 服务器上没有对应的配置信息,则使用本地的配置文件)。
- 更重要的是,当配置发生变化时(例如修改数据库连接),Nacos 可以实现 热更新,服务无需重启就可以自动加载新的配置,确保服务配置的动态调整。
- 服务健康检查
- Nacos 会定期检查注册到它的服务的健康状态,如果某个微服务宕机或无法访问,Nacos 会自动剔除掉这个服务的注册信息,避免客户端访问失效的服务。
- 分布式锁
- Nacos 支持分布式锁机制,帮助解决微服务间的并发控制问题。
- 多种数据源支持
- Nacos 支持多种配置数据源,包括 数据库、文件、KV 存储等,方便集成和扩展。
Nacos 的数据存储在哪里?
Nacos 默认使用 嵌入式数据库 来存储数据,但在实际生产环境中,存在大规模的并发请求,Nacos 默认的嵌入式数据库没有高可用性保障,因此往往选择将数据存储到 外部数据库(如 MySQL)中。
服务发现和容错
传统的体系架构中,服务与服务之间的发现和调用是通过查名实现的,因此我们需要一台查名服务器,在服务器上存储每个服务部署的服务器的 ip 地址。
在微服务体系结构中,因为原来的单体项目被拆分成了多个微服务,服务与服务之间的相互发现以及调用会变得非常频繁,因此整个系统的关键就变成了查名服务器的性能。
在 Nacos 中,提出了一个很聪明的解决方法:不依靠查名服务器完成查名,而是依靠客户端缓存来完成查名。这样的解决方法使得即使 Nacos 服务器 down 掉了,其他微服务也能正常通过客户端缓存来完成查名操作。
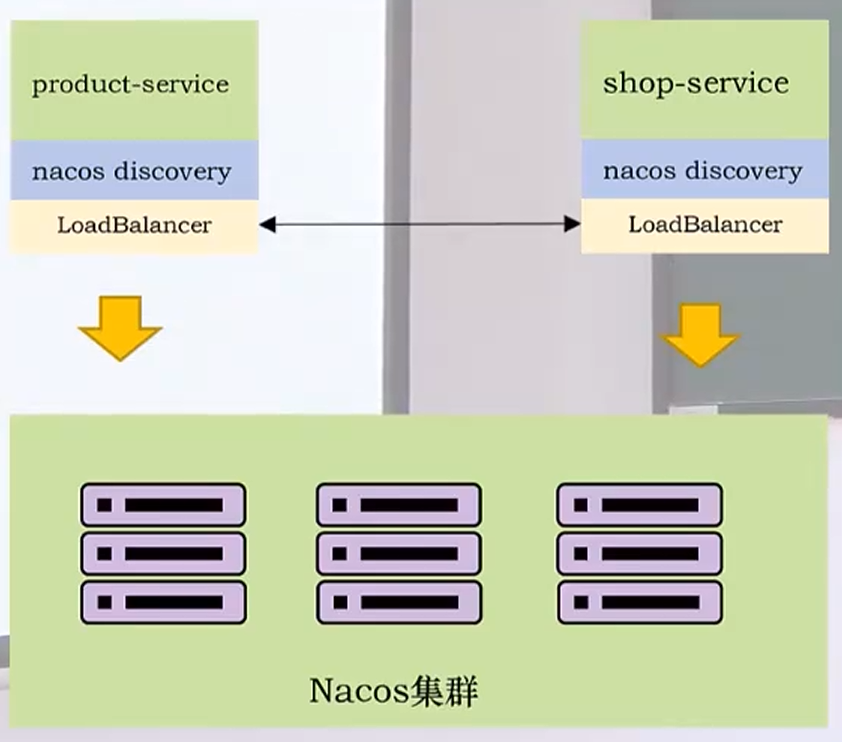
以上图为例,product 服务和 shop 服务存在调用关系,当两个服务启动时,会通过 nacos discovery 将自己的配置信息注册到 Nacos 集群中,在注册的同时,还会将 Nacos 集群中所有的查名信息拉到本地,因此当 product 需要调用 shop 服务时,并不会通过 Nacos 集群去查名,而是直接查本地的客户端缓存,然后去调用 shop 服务的代码。
但是当我们增加新的微服务时,本地的客户端缓存就会存在数据不一致的情况,这个问题怎么解决?其实在每个微服务的 nacos discovery 中,都会定时向 Nacos 集群发送自己的心跳数据,保证 Nacos 集群能够掌握所有微服务的运行状态,在发送心跳数据后,Nacos 集群就会把最新的查名数据推送到对应的客户端。
在上图中的 nacos discovery 下方还有一个 LoadBalancer ,这是用来实现动态负载平衡的。如上面所说的,微服务之间的查名是在客户端本地做的,因此动态负载平衡也不会经过 Nacos 服务器集群,直接在客户端本地进行(动态负载平衡算法用的较多的是轮询和随机)。
熔断器
服务雪崩
在微服务架构中,一个服务的故障或性能问题可能会逐渐引发多个服务连锁反应,最终导致整个系统的崩溃或大规模不可用。它通常是由于服务之间高度耦合,某个服务的失败会迅速传播,造成大量下游服务无法正常工作,从而引发整个系统的崩溃。
举个例子:一个电商平台的订单服务、支付服务、商品服务和库存服务都属于不同的微服务,如果支付服务出现了故障,导致它不能及时响应,订单服务会等待支付响应,库存服务也可能因为订单服务的失败无法处理库存请求。最终,支付服务的问题会影响到多个服务,形成服务雪崩。
熔断器机制
熔断器机制是一种 容错机制,用于保护系统中的服务免受雪崩效应的影响。熔断器的核心作用是,当某个服务的故障超过一定阈值时,它会自动断开对该服务的请求,避免问题继续蔓延到其他服务。熔断器会根据服务的健康状态切换不同的状态(如关闭、打开、半开)。
熔断器的工作原理:
- 关闭状态(Closed):当服务正常时,熔断器处于关闭状态,所有请求会正常通过。如果在短时间内出现一定数量的失败请求(如超时、500 错误等),熔断器会切换到 打开状态。
- 打开状态(Open):当服务失败率超过阈值,熔断器进入打开状态,所有对该服务的请求将被 拒绝。在此期间,系统不会继续尝试请求已失败的服务,避免请求积压,减轻系统负担,保护系统不被进一步拖垮。
- 半开状态(Half-Open):在一定时间后,熔断器进入半开状态,允许一小部分请求通过。这些请求用于测试该服务是否已经恢复正常。如果请求成功,熔断器会重新切换到关闭状态;如果失败,则继续保持打开状态。
还是上面的例子,假设支付服务出现问题,熔断器机制会启动,在一定时间内拒绝所有对支付服务的请求。这样,订单服务、库存服务等不会继续尝试访问支付服务,避免它们的请求堆积,减少对系统其他部分的影响。当熔断器进入半开状态时,会进行少量请求测试支付服务是否恢复正常,如果成功,则允许流量恢复,进入关闭状态。