
[TOC]
主要特征
- 语法简单,自带 gc
- 静态编译,编译好后在服务器直接运行
- 简单的思想,没有继承、多态、类等
- 语法层支持并发,拥有同步并发的 channel 类型,使并发开发变得非常方便
- 内置类型丰富,函数多返回值
- 反射
Golang 内置类型和函数
内置类型
值类型
bool
int(32 or 64), int8, int16, int32, int64
uint(32 or 64), uint8(byte), uint16, uint32, uint64
float32, float64
string
complex64, complex128
array -- 固定长度的数组
引用类型(指针类型)
slice -- 序列数组(最常用)
map -- 映射
chan -- 管道
内置函数
Go 语言拥有一些不需要进行导入操作就可以使用的内置函数。它们有时可以针对不同的类型进行操作,例如:len、cap 和 append,或必须用于系统级的操作,例如:panic。因此,它们需要直接获得编译器的支持。
append -- 用来追加元素到数组、slice中,返回修改后的数组、slice
close -- 主要用来关闭channel
delete -- 从map中删除key对应的value
panic -- 停止常规的goroutine (panic和recover:用来做错误处理)
recover -- 允许程序定义goroutine的panic动作
imag -- 返回complex的实部 (complex、real imag:用于创建和操作复数)
real -- 返回complex的虚部
make -- 用来分配内存,返回Type本身(只能应用于slice, map, channel)
new -- 用来分配内存,主要用来分配值类型,比如int、struct。返回指向Type的指针
cap -- capacity是容量的意思,用于返回某个类型的最大容量(只能用于切片和 map)
copy -- 用于复制和连接slice,返回复制的数目
len -- 来求长度,比如string、array、slice、map、channel ,返回长度
print、println -- 底层打印函数,在部署环境中建议使用 fmt 包
内置接口
type error interface { //只要实现了Error()函数,返回值为String的都实现了err接口
Error() String
}
init 函数和 main 函数
init 函数
go 语言中 init 函数用于包(package)的初始化,该函数是 go 语言的一个重要特性。
init 函数有如下特征:
init函数是用于程序执行前做包初始化的函数,比如初始化包里的变量等- 每个包可以拥有多个
init函数 - 包的每个源文件也可以拥有多个
init函数 - 同一个包中多个
init函数的执行顺序 go 语言没有明确的说明 - 不同包的
init函数按照包导入的依赖关系决定该初始化函数的执行顺序 init函数不能被其他函数调用,而是在main函数执行之前自动被调用
main 函数
Go语言程序的默认入口函数(主函数):func main()
func main() {
// 函数体
}
两种函数的异同
- 相同点:
- 两个函数在定义时不能有任何的参数和返回值,且 Go 程序自动调用
- 不同点:
init函数可以应用于任意包中,且可以重复定义多个main函数只能用于main包中,且只能定义一个
- 两个函数的执行顺序:
- 同一个 go 文件中的
init()调用顺序是从上到下的 - 同一个 package 中不同文件是按文件名字符串比较 “从小到大” 顺序调用各文件中的
init()函数 - 对于不同的 package ,如果不相互依赖的话,按照 main 包中 “先 import 的后调用” 的顺序调用包中的
init(),如果 package 存在依赖,则先调用最早被以来的 package 中的init(),最后调用 main 函数
- 同一个 go 文件中的
运算符
- 算术运算符
| 运算符 | 描述 |
|---|---|
| + | 相加 |
| - | 相减 |
| * | 相乘 |
| / | 相除 |
| % | 求余 |
注意: ++(自增)和–(自减)在Go语言中是单独的语句,并不是运算符
- 关系运算符
| 运算符 | 描述 |
|---|---|
| == | 检查两个值是否相等,如果相等返回 True 否则返回 False |
| != | 检查两个值是否不相等,如果不相等返回 True 否则返回 False |
| > | 检查左边值是否大于右边值,如果是返回 True 否则返回 False |
| >= | 检查左边值是否大于等于右边值,如果是返回 True 否则返回 False |
| < | 检查左边值是否小于右边值,如果是返回 True 否则返回 False |
| <= | 检查左边值是否小于等于右边值,如果是返回 True 否则返回 False |
- 逻辑运算符
| 运算符 | 描述 |
|---|---|
| && | 逻辑 AND 运算符。 如果两边的操作数都是 True,则为 True,否则为 False |
| || | 逻辑 OR 运算符。 如果两边的操作数有一个 True,则为 True,否则为 False |
| ! | 逻辑 NOT 运算符。 如果条件为 True,则为 False,否则为 True |
- 位运算符
| 运算符 | 描述 |
|---|---|
| & | 参与运算的两数各对应的二进位相与(两位均为1才为1) |
| | | 参与运算的两数各对应的二进位相或(两位有一个为1就为1) |
| ^ | 参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1(两位不一样则为1) |
| « | 左移 n 位就是乘以 2 的 n 次方。“a « b” 是把 a 的各二进位全部左移 b 位,高位丢弃,低位补 0 |
| » | 右移 n 位就是除以 2 的 n 次方。“a » b” 是把 a 的各二进位全部右移 b 位 |
- 赋值运算符
| 运算符 | 描述 |
|---|---|
| = | 将一个表达式的值赋给一个左值 |
| += | 相加后再赋值 |
| -= | 相减后再赋值 |
| *= | 相乘后再赋值 |
| /= | 相除后再赋值 |
| %= | 求余后再赋值 |
| «= | 左移后赋值 |
| »= | 右移后赋值 |
| &= | 按位与后赋值 |
| |= | 按位或后赋值 |
| ^= | 按位异或后赋值 |
下划线
“_” 是特殊标识符,用来忽略结果
-
下划线在
import中-
当导入一个包时,该包下的文件里所有的
init()函数都会被执行。如果我们仅仅希望它执行init()函数,不想把整个包都导入进来,就可以使用import _ 包路径来引用该包 -
示例 1:
-
代码结构
src | +--- main.go | +--- hello | +--- hello.gopackage main import _ "./hello" func main() { // hello.Print() //编译报错:./main.go:6:5: undefined: hello } -
hello.gopackage hello import "fmt" func init() { fmt.Println("imp-init() come here.") } func Print() { fmt.Println("Hello!") } -
输出结果:
imp-init() come here.
-
-
示例 2:
import "database/sql" import _ "github.com/go-sql-driver/mysql"第二个
import就是不直接使用 mysql 包,只是执行这个包的init()函数,把 mysql 的驱动注册到 sql 包里,然后程序里就可以使用 sql 包来访问 mysql 数据库了
-
-
下划线在代码中
package main import ( "os" ) func main() { buf := make([]byte, 1024) f, _ := os.Open("/Users/***/Desktop/text.txt") defer f.Close() for { n, _ := f.Read(buf) if n == 0 { break } os.Stdout.Write(buf[:n]) } }- 解释 1:下划线意思是忽略这个变量,比如:
os.Open,返回值为*os.File, error- 普通写法是:
f, err := os.Open("xxxxxx") - 如果此时不需要知道返回的错误值,就可以用:
f, _ := os.Open("xxxxxx"),如此就忽略了 error 变量
- 普通写法是:
- 解释 2:下划线作为占位符,意思是那个位置本应赋给某个值,但是咱们不需要这个值,所以就把该值赋给下划线,意思是丢掉不要,这样编译器可以更好的优化。
- 任何类型的单个值都可以丢给下划线,这种情况是占位用的,比如方法返回两个结果,而你只想要一个结果,那另一个就用 “_” 占位
- 解释 1:下划线意思是忽略这个变量,比如:
变量与常量
变量
Go 语言中的变量需要声明后才能使用,同一作用域内不支持重复声明。并且 Go 语言的变量声明后必须使用
Go 语言的变量声明格式为:
var 变量名 变量类型
变量声明以关键字 var 开头,变量类型放在变量的后面,行尾无需分号:
var name string
var age int
var ok bool
每声明一个变量就写一个 var 比较繁琐,Go 语言还支持批量变量声明:
var (
a string
b int
c bool
d float32
)
Go 语言在声明变量的时候,会自动对变量对应的内存区域进行初始化操作。每个变量会被初始化成其类型的默认值,例如: 整型和浮点型变量的默认值为 0 ,字符串变量的默认值为空字符串,布尔型变量默认为false。切片、函数、指针变量的默认为 nil
当然我们也可在声明变量的时候为其指定初始值。变量初始化的标准格式如下:
var 变量名 类型 = 表达式
// example
var name string = "hello"
var sex int = 1
或者一次初始化多个变量:
var name, sex = "hello", 1
类型推导:有时候我们会将变量的类型省略,这个时候编译器会根据等号右边的值来推导变量的类型完成初始化
var name = "hello"
var sex = 1
短变量声明:在函数内部,可以使用更简略的 := 方式声明并初始化变量
package main
import (
"fmt"
)
// 全局变量m
var m = 100
func main() {
n := 10
m := 200 // 此处声明局部变量m
fmt.Println(m, n)
}
匿名变量:在使用多重赋值时,如果想要忽略某个值,可以使用匿名变量(anonymous variable)。 匿名变量用一个下划线 _ 表示
func foo() (int, string) {
return 10, "hello"
}
func main() {
x, _ := foo()
_, y := foo()
fmt.Println("x=", x)
fmt.Println("y=", y)
}
匿名变量不占用命名空间,不会分配内存,所以匿名变量之间不存在重复声明(在 Lua 等编程语言里,匿名变量也被叫做哑元变量)
注意事项:
- 函数外的每个语句必须以关键字开始(var、const、func 等)
:=不能在函数外使用_多用于占位,表示忽略值
常量
相对于变量,常量是恒定不变的值,多用于定义程序运行期间不会改变的那些值。 常量的声明和变量声明非常类似,只是把 var 换成了 const ,常量在定义的时候必须赋值
const pi = 3.1415
const e = 2.7182
声明了 pi 和 e 这两个常量之后,在整个程序运行期间它们的值都不能再发生变化了
多个常量也可以一起声明:
const (
pi = 3.1415
e = 2.7182
)
const 同时声明多个常量时,如果省略了值则表示和上面一行的值相同
const (
n1 = 100
n2
n3
)
常量 n1 、n2、n3 的值均为 100
iota:iota 是 Go 语言的常量计数器,只能在常量的表达式中使用。 iota 在 const 关键字出现时将被重置为 0 。const 中每新增一行常量声明将使 iota 计数一次(iota 可理解为 const 语句块中的行索引)。 使用 iota 能简化定义,在定义枚举时很有用
const (
n1 = 100 // 0
n2 // 1
n3 // 2
)
使用 _ 跳过某些值:
const (
n1 = 100 // 0
n2 // 1
_
n3 // 3
)
使用示例:
const (
n1 = iota // 0
n2 = 100
n3 = iota // 2
n4 // 3
)
const n5 = iota // 0
定义数量级:
const (
_ = iota
KB = 1 << (10 * iota)
MB = 1 << (10 * iota)
GB = 1 << (10 * iota)
TB = 1 << (10 * iota)
PB = 1 << (10 * iota)
)
多个 iota 定义在一行:
const (
a, b = iota + 1, iota + 2 //1,2
c, d //2,3
e, f //3,4
)
基本类型
-
整形:整型分为以下两个大类: 按长度分为:
int8、int16、int32、int64对应的无符号整型:uint8、uint16、uint32、uint64。其中,uint8就是byte型,int16对应C语言中的short型,int64对应C语言中的long型 -
浮点型:Go语言支持两种浮点型数:
float32和float64。这两种浮点型数据格式遵循IEEE 754标准:float32的浮点数的最大范围约为3.4e38,可以使用常量定义:math.MaxFloat32。float64的浮点数的最大范围约为1.8e308,可以使用一个常量定义:math.MaxFloat64 -
复数:
complex64和complex128,复数有实部和虚部,complex64的实部和虚部为 32 位,complex128的实部和虚部为 64 位 -
布尔值:Go语言中以
bool类型进行声明布尔型数据,布尔型数据只有true和false两个值- 注意:布尔类型变量的默认值为
false,Go 语言中不允许将整型强制转换为布尔型,布尔型无法参与数值运算,也无法与其他类型进行转换
- 注意:布尔类型变量的默认值为
-
字符串:Go 语言中的字符串以原生数据类型出现,使用字符串就像使用其他原生数据类型(int、bool、float32、float64 等)一样。 Go 语言里的字符串的内部实现使用 UTF-8 编码。 字符串的值为双引号中的内容,可以在Go语言的源码中直接添加非
ASCII码字符,例如:s1 := "hello" s2 := "你好" // 非 ASCII码 -
多行字符串:Go 语言中使用反引号定义多行字符串,例如:
s1 := `第一行 第二行 第三行 ` fmt.Println(s1) -
字符串常用操作:
| 方法 | 介绍 |
|---|---|
| len(str) | 求长度 |
| + 或 fmt.Sprintf | 拼接字符串 |
| strings.Split | 分割字符串 |
| strings.Contains | 判断是否包含 |
| strings.HasPrefix, strings.HasSuffix | 前缀/后缀判断 |
| strings.Index(), strings.LastIndex() | 子串出现的位置 |
| strings.Join(a[]string, sep string) | join 操作 |
-
byte 和 rune 类型:
-
组成每个字符串的元素叫做“字符”,可以通过遍历或者单个获取字符串元素获得字符。 字符用单引号
’包裹起来,如:var a := '中' var b := 'x' -
Go 语言的字符有以下两种:
uint8类型,或者叫byte型,代表了 ASCII 码的一个字符rune类型,代表一个 UTF-8 字符
-
当需要处理中文、日文或者其他复合字符时,则需要用到
rune类型。rune类型实际是一个int32。 Go 使用了特殊的rune类型来处理Unicode,让基于Unicode的文本处理更为方便,也可以使用byte型进行默认字符串处理,性能和扩展性都有照顾// 遍历字符串 func traversalString() { s := "pprof.cn博客" for i := 0; i < len(s); i++ { //byte fmt.Printf("%v(%c) ", s[i], s[i]) } fmt.Println() for _, r := range s { //rune fmt.Printf("%v(%c) ", r, r) } fmt.Println() }输出如下:
112(p) 112(p) 114(r) 111(o) 102(f) 46(.) 99(c) 110(n) 229(å) 141() 154() 229(å) 174(®) 162(¢) 112(p) 112(p) 114(r) 111(o) 102(f) 46(.) 99(c) 110(n) 21338(博) 23458(客)- 因为 UTF8 编码下一个中文汉字由 3~4 个字节组成,所以我们不能简单的按照字节去遍历一个包含中文的字符串,否则就会出现上面输出中第一行的结果
- 字符串底层是一个 byte 数组,所以可以和 []byte 类型相互转换。 rune 类型用来表示 UTF-8 字符,一个 rune 字符由一个或多个 byte 组成,注意:字符串是不能修改的
-
-
修改字符串:要修改字符串,需要先将其转换成
[]rune或[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组func changeString() { s1 := "hello" // 强制类型转换 byteS1 := []byte(s1) byteS1[0] = 'H' fmt.Println(string(byteS1)) // 输出:Hello s2 := "博客" runeS2 := []rune(s2) runeS2[0] = '狗' fmt.Println(string(runeS2)) // 输出:狗客 } -
类型转换:Go 语言中只有强制类型转换,没有隐式类型转换。该语法只能在两个类型之间支持相互转换的时候使用
-
基本语法:
T(表达式)其中,T表示要转换的类型。表达式包括变量、复杂算子和函数返回值等
比如计算直角三角形的斜边长时使用 math 包的 Sqrt() 函数,该函数接收的是 float64 类型的参数,而变量 a 和 b 都是 int 类型的,这个时候就需要将 a 和 b 强制类型转换为 float64 类型
func sqrtDemo() { var a, b = 3, 4 var c int // math.Sqrt()接收的参数是float64类型,需要强制转换 c = int(math.Sqrt(float64(a*a + b*b))) fmt.Println(c) }
-
数组 Array
-
数组定义:
var a [len]int- 比如:
var a [5]int,数组长度必须是常量,且是类型的组成部分。一旦定义,长度不能变 - 长度是数组类型的一部分,因此,
var a[5]int和var a[10]int是不同的类型 - 数组是值类型,赋值和传参会复制整个数组,而不是指针。因此改变副本的值,不会改变本身的值
- 指针数组
[n]*T,数组指针*[n]T
- 比如:
-
一维数组
// 全局: var arr0 [5]int = [5]int{1, 2, 3} var arr1 = [5]int{1, 2, 3, 4, 5} var arr2 = [...]int{1, 2, 3, 4, 5, 6} var str = [5]string{3: "hello world", 4: "tom"} // 局部: a := [3]int{1, 2} // 未初始化元素值为 0。 b := [...]int{1, 2, 3, 4} // 通过初始化值确定数组长度。 c := [5]int{2: 100, 4: 200} // 使用索引号初始化元素。 d := [...]struct { name string age uint8 }{ {"user1", 10}, // 可省略元素类型。 {"user2", 20}, // 别忘了最后一行的逗号。 }package main import ( "fmt" ) var arr0 [5]int = [5]int{1, 2, 3} var arr1 = [5]int{1, 2, 3, 4, 5} var arr2 = [...]int{1, 2, 3, 4, 5, 6} var str = [5]string{3: "hello world", 4: "tom"} func main() { a := [3]int{1, 2} // 未初始化元素值为 0。 b := [...]int{1, 2, 3, 4} // 通过初始化值确定数组长度。 c := [5]int{2: 100, 4: 200} // 使用引号初始化元素。 d := [...]struct { name string age uint8 }{ {"user1", 10}, // 可省略元素类型。 {"user2", 20}, // 别忘了最后一行的逗号。 } fmt.Println(arr0, arr1, arr2, str) fmt.Println(a, b, c, d) }输出结果: [1 2 3 0 0] [1 2 3 4 5] [1 2 3 4 5 6] [ hello world tom] [1 2 0] [1 2 3 4] [0 0 100 0 200] [{user1 10} {user2 20}] -
多维数组 & 多维数组遍历
- 参考:https://www.topgoer.com/go%E5%9F%BA%E7%A1%80/%E6%95%B0%E7%BB%84Array.html
-
数组拷贝和传参
package main import "fmt" func printArr(arr *[5]int) { arr[0] = 10 // 循环中 i 是元素下标,v 是元素数值 for i, v := range arr { fmt.Println(i, v) } } func main() { var arr1 [5]int printArr(&arr1) fmt.Println(arr1) arr2 := [...]int{2, 4, 6, 8, 10} printArr(&arr2) fmt.Println(arr2) }输出结果: 0 10 1 0 2 0 3 0 4 0 [10 0 0 0 0] 0 10 1 4 2 6 3 8 4 10 [10 4 6 8 10]
切片 Slice
-
slice并不是数组或数组指针。它通过内部指针和相关属性引用数组片段,以实现变长方案-
切片是数组的一个引用,但自身是结构体,通过值拷贝传递
-
切片的长度可以改变,因此切片是一个可变数组
-
切片遍历方式和数组一样,可以用
len()求长度,表示可用元素数量,读写操作不能超过该限制 -
cap()可以求出切片最大扩张容量,不能超出数组限制:0 <= len(slice) <= len(array),其中array是slice引用的数组 -
定义:
var 变量名 []类型,比如:var str []string、var arr []int -
如果
slice == nil,那么len()、cap()结果都等于 0
-
-
创建切片的各种方式
package main import "fmt" func main() { //1.使用 var 声明切片 s1,s1 是一个 nil 切片,没有分配内存 var s1 []int if s1 == nil { fmt.Println("是空") } else { fmt.Println("不是空") } // 2.使用 := 简短声明,创建切片 s2 并初始化为空切片 // 空切片与 nil 切片不同,空切片底层数组已分配内存,但是容量为 0,而 nil 切片没有分配内存 s2 := []int{} // 3.使用 make() 创建切片,可以指定切片长度和容量 var s3 []int = make([]int, 0) fmt.Println(s1, s2, s3) // 4.初始化赋值 var s4 []int = make([]int, 0, 0) fmt.Println(s4) s5 := []int{1, 2, 3} fmt.Println(s5) // 5.从数组切片 arr := [5]int{1, 2, 3, 4, 5} var s6 []int // 前包后不包 s6 = arr[1:4] fmt.Println(s6) }注意:切片的长度是当前切片存储的元素数量,通过
len()获取切片长度;切片容量是从切片的起始位置到底层数组的末尾的元素数量,也就是切片能容纳的元素的最大数量,通过cap()获取切片长度 -
切片初始化
// 全局: var arr = [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} var slice0 []int = arr[start:end] var slice1 []int = arr[:end] var slice2 []int = arr[start:] var slice3 []int = arr[:] var slice4 = arr[:len(arr)-1] //去掉切片的最后一个元素 // 局部: arr2 := [...]int{9, 8, 7, 6, 5, 4, 3, 2, 1, 0} slice5 := arr[start:end] slice6 := arr[:end] slice7 := arr[start:] slice8 := arr[:] slice9 := arr[:len(arr)-1] //去掉切片的最后一个元素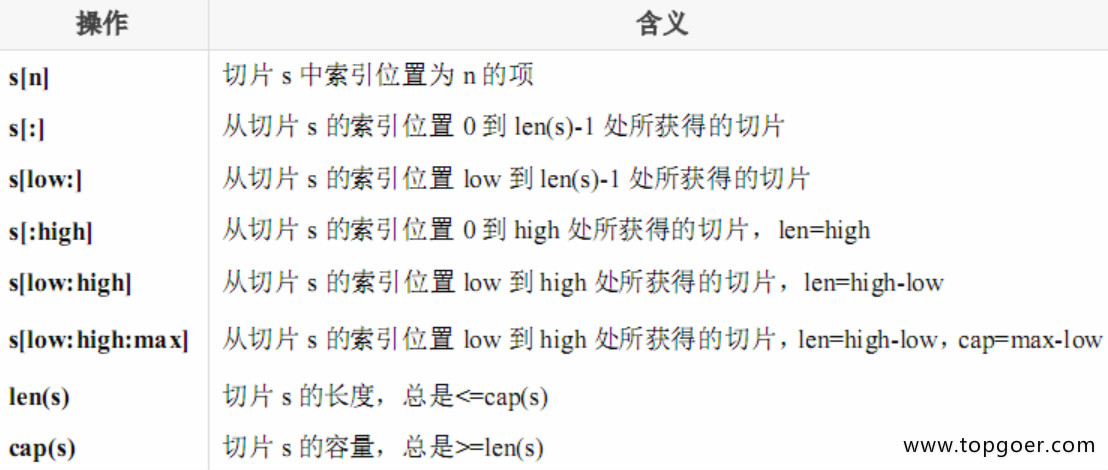
package main import ( "fmt" ) var arr = [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} var slice0 []int = arr[2:8] var slice1 []int = arr[0:6] //可以简写为 var slice []int = arr[:end] var slice2 []int = arr[5:10] //可以简写为 var slice[]int = arr[start:] var slice3 []int = arr[0:len(arr)] //var slice []int = arr[:] var slice4 = arr[:len(arr)-1] //去掉切片的最后一个元素 func main() { fmt.Printf("全局变量:arr %v\n", arr) fmt.Printf("全局变量:slice0 %v\n", slice0) fmt.Printf("全局变量:slice1 %v\n", slice1) fmt.Printf("全局变量:slice2 %v\n", slice2) fmt.Printf("全局变量:slice3 %v\n", slice3) fmt.Printf("全局变量:slice4 %v\n", slice4) fmt.Printf("-----------------------------------\n") arr2 := [...]int{9, 8, 7, 6, 5, 4, 3, 2, 1, 0} slice5 := arr[2:8] slice6 := arr[0:6] //可以简写为 slice := arr[:end] slice7 := arr[5:10] //可以简写为 slice := arr[start:] slice8 := arr[0:len(arr)] //slice := arr[:] slice9 := arr[:len(arr)-1] //去掉切片的最后一个元素 fmt.Printf("局部变量: arr2 %v\n", arr2) fmt.Printf("局部变量: slice5 %v\n", slice5) fmt.Printf("局部变量: slice6 %v\n", slice6) fmt.Printf("局部变量: slice7 %v\n", slice7) fmt.Printf("局部变量: slice8 %v\n", slice8) fmt.Printf("局部变量: slice9 %v\n", slice9) }输出结果: 全局变量:arr [0 1 2 3 4 5 6 7 8 9] 全局变量:slice0 [2 3 4 5 6 7] 全局变量:slice1 [0 1 2 3 4 5] 全局变量:slice2 [5 6 7 8 9] 全局变量:slice3 [0 1 2 3 4 5 6 7 8 9] 全局变量:slice4 [0 1 2 3 4 5 6 7 8] ----------------------------------- 局部变量: arr2 [9 8 7 6 5 4 3 2 1 0] 局部变量: slice5 [2 3 4 5 6 7] 局部变量: slice6 [0 1 2 3 4 5] 局部变量: slice7 [5 6 7 8 9] 局部变量: slice8 [0 1 2 3 4 5 6 7 8 9] 局部变量: slice9 [0 1 2 3 4 5 6 7 8]