
前言
我们所熟悉的DFS问题通常是在树或者图结构上进行的。本文讨论的DFS问题是在一种「网格」结构中进行的。岛屿问题是这类网格DFS问题的典型代表。网格结构遍历起来要比二叉树更加复杂,如果没有掌握一定的方法,DFS代码容易写得冗杂。
本文将以岛屿问题为例,展示网格类问题DFS通用思路,以及如何让代码变得简洁。
网格类问题的DFS遍历方法
基本概念
我们首先明确一下岛屿问题中的网格结构是如何定义的,以方便我们后面的讨论。
网格问题是由 m × n 个小方格组成一个网格,每个小方格与其上下左右四个方格认为是相邻的,要在这样的网格上进行某种搜索。
岛屿问题是一类典型的网格问题。每个格子中的数字可能是 0 或者 1。我们把数字为 0 的格子看成海洋格子,数字为 1 的格子看成陆地格子,这样相邻的陆地格子就连接成一个岛屿。
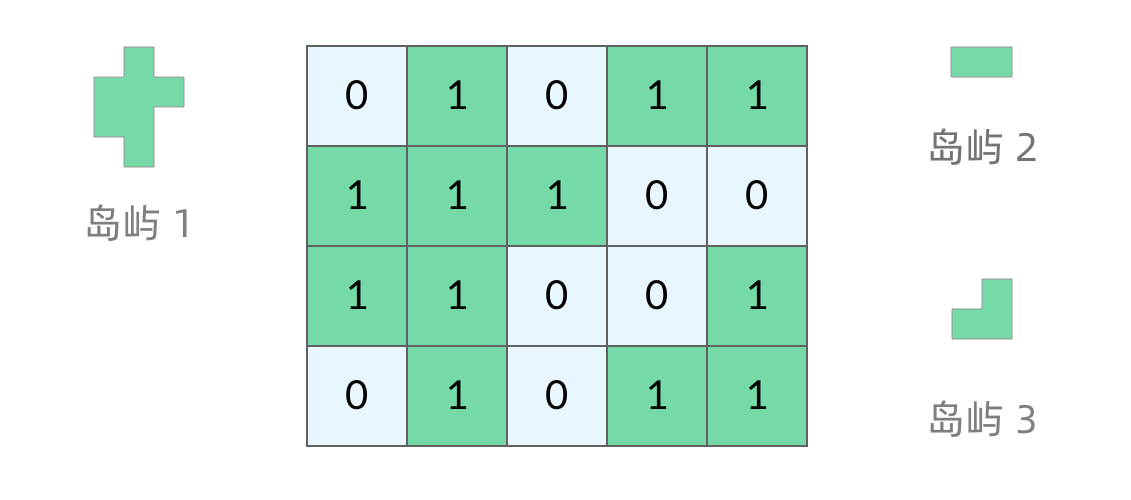
在这样一个设定下,就出现了各种岛屿问题的变种,包括岛屿的数量、面积、周长等。不过这些问题基本都可以用DFS遍历来解决。
DFS的基本结构
网格问题要比二叉树结构稍微复杂一些,它其实是一种简化版的图结构。要写好网格上的DFS遍历,我们首先要理解二叉树上的DFS遍历方法,再类比写出网格结构上的DFS遍历。我们写的二叉树DFS遍历一般是这样的:
void traverse(TreeNode root) {
// 判断 base case
if (root == null) {
return;
}
// 访问两个相邻结点:左子结点、右子结点
traverse(root.left);
traverse(root.right);
}
可以看到,二叉树的DFS有两个要素:「访问相邻结点」和「判断 base case」。
- 访问相邻节点:二叉树的相邻节点比较简单,只有左子节点和右子节点两个。二叉树本身就是一个递归定义的结构:一棵二叉树,它的左子树和右子树也是一棵二叉树。那么我们的DFS遍历只需要递归调用左子树和右子树即可。
- 判断 base case:一般来说,二叉树遍历的
base case是root == null。这样一个条件判断其实有两个含义:- 一方面,这表示
root指向的子树为空,不需要再向下遍历了。 - 另一方面,在
root == null的时候及时返回,可以让后面的root.left和root.right操作不会出现空指针异常。
- 一方面,这表示
对于网格上的DFS,我们完全可以参考二叉树的DFS,写出网格DFS的两个要素:
- 首先,网格结构中的格子有多少相邻节点?答案是上下左右四个。对于格子
(r, c)来说(r和c分别代表行坐标和列坐标),四个相邻的格子分别是(r-1, c)、(r+1, c)、(r, c-1)、(r, c+1)。换句话说,网格结构是「四叉」的
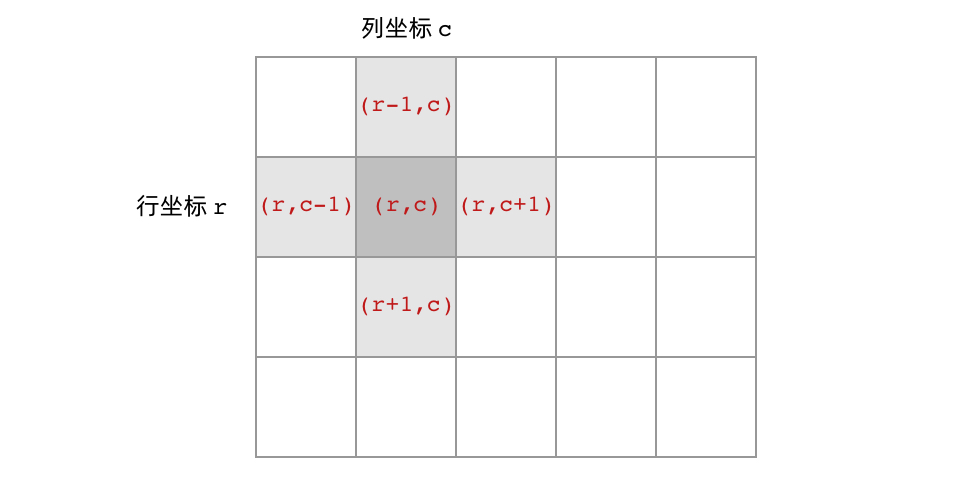
- 其次,网格DFS中的
base case是什么?从二叉树的base case对应过来,应该是网格中不需要继续遍历、grid[r][c]会出现数组下标越界异常的格子,也就是那些超出网格范围的格子。
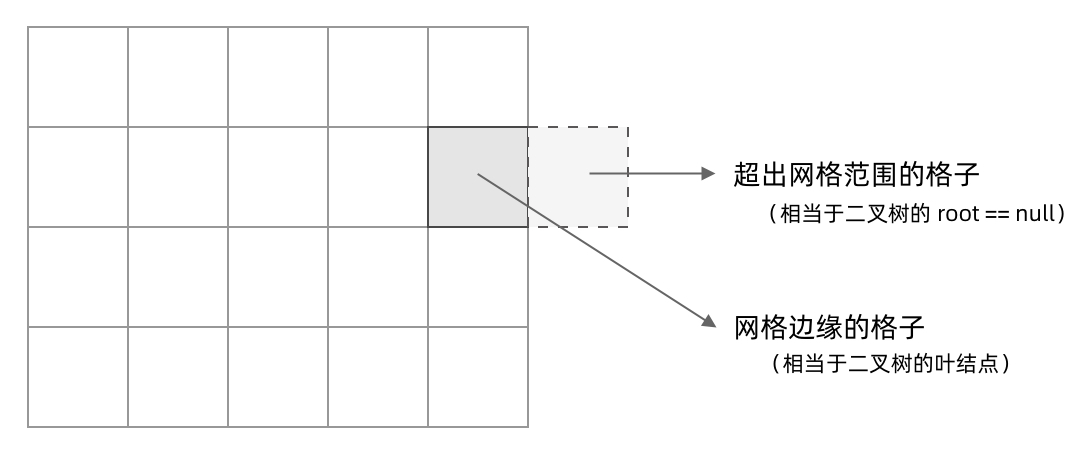
这种方法可以称为「先污染后治理」——不管当前是在哪个格子,先往四个方向走一步再说,如果发现走出了网格范围,再赶紧返回。这和二叉树的遍历方法是一样的,先递归调用,发现root == null 再返回。
这样,我们得到了网格DFS便利的框架代码:
void dfs(int[][] grid, int r, int c) {
// 判断 base case
// 如果坐标 (r, c) 超出了网格范围,直接返回
if (!inArea(grid, r, c)) {
return;
}
// 访问上、下、左、右四个相邻结点
dfs(grid, r - 1, c);
dfs(grid, r + 1, c);
dfs(grid, r, c - 1);
dfs(grid, r, c + 1);
}
// 判断坐标 (r, c) 是否在网格中
boolean inArea(int[][] grid, int r, int c) {
return 0 <= r && r < grid.length
&& 0 <= c && c < grid[0].length;
}
如何避免重复遍历?
网格结构的DFS与二叉树的DFS最大的不同之处在于,遍历中可能遇到遍历过的节点。这是因为,网格结构本质上是一个「图」,我们可以把每个格子看作图中的节点,每个节点有上下左右四条边。在图中遍历时,自然可能遇到重复遍历的节点。
这时候,DFS可能会不停的「兜圈子」,永远停不下来。
如何避免这样的重复遍历?答案是标记已经遍历过的格子。以岛屿问题为例,我们需要在所有值为 1 的陆地格子上进行DFS。每走过一个陆地格子,就把格子的值改为 2,这样当我们遇到 2 的时候,就知道这是遍历过的格子了。也就是说,每个格子可能取三个值:
- 0——海洋格子
- 1——陆地格子(未遍历过)
- 2——陆地格子(已遍历过)
我们在框架代码中加入避免重复遍历的语句:
void dfs(int[][] grid, int r, int c) {
// 判断 base case
if (!inArea(grid, r, c)) {
return;
}
// 如果这个格子不是岛屿,直接返回
if (grid[r][c] != 1) {
return;
}
grid[r][c] = 2; // 将格子标记为「已遍历过」
// 访问上、下、左、右四个相邻结点
dfs(grid, r - 1, c);
dfs(grid, r + 1, c);
dfs(grid, r, c - 1);
dfs(grid, r, c + 1);
}
// 判断坐标 (r, c) 是否在网格中
boolean inArea(int[][] grid, int r, int c) {
return 0 <= r && r < grid.length
&& 0 <= c && c < grid[0].length;
}
这样,我们就得到了一个岛屿问题、乃至各种网格问题的通用DFS遍历方法。
注意:在一些题解中,可能会把「已遍历过的陆地格子」标记为和海洋格子一样的 0,即遍历完一个陆地格子就让陆地「沉没」为海洋。这种方法看似很巧妙,但实际上有很大隐患,因为这样我们就无法区分「海洋格子」和「已遍历过的陆地格子」了。如果题目更复杂一点,这很容易出 bug。
例题1:岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [
["1","1","1","1","0"],
["1","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"]
]
输出:1
示例 2:
输入:grid = [
["1","1","0","0","0"],
["1","1","0","0","0"],
["0","0","1","0","0"],
["0","0","0","1","1"]
]
输出:3
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 300grid[i][j]的值为'0'或'1'
代码
class Solution {
public:
vector<pair<int, int>> dir = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
void dfs(vector<vector<char>>& grid, int x, int y) {
if (!judge(grid, x, y)) return;
if (grid[x][y] == '1') {
grid[x][y] = '2';
for (int i = 0; i < 4; ++i) {
int dirx = x + dir[i].first;
int diry = y + dir[i].second;
dfs(grid, dirx, diry);
}
}
}
bool judge(vector<vector<char>>& grid, int x, int y) {
int row = grid.size();
int col = grid[0].size();
if (x >= row || x < 0 || y >= col || y < 0) return false;
return true;
}
int numIslands(vector<vector<char>>& grid) {
int ans = 0;
int row = grid.size(), col = grid[0].size();
for (int i = 0; i < row; ++i) {
for (int j = 0; j < col; ++j) {
if (grid[i][j] == '1') {
dfs(grid, i, j);
ans++;
}
}
}
return ans;
}
};
例题2:字母迷宫
字母迷宫游戏初始界面记作 m x n 二维字符串数组 grid,请判断玩家是否能在 grid 中找到目标单词 target。
注意:寻找单词时 必须 按照字母顺序,通过水平或垂直方向相邻的单元格内的字母构成,同时,同一个单元格内的字母 不允许被重复使用 。

示例 1:
输入:grid = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], target = "ABCCED"
输出:true
示例 2:
输入:grid = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], target = "SEE"
输出:true
示例 3:
输入:grid = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], target = "ABCB"
输出:false
提示:
m == grid.lengthn = grid[i].length1 <= m, n <= 61 <= target.length <= 15grid和target仅由大小写英文字母组成
思路
思路很好想,遍历表中所有的字母,当前字母为起点进行 DFS ,逐位地匹配 target 字符串,如果还没有达到 target 的长度就出现了不同,说明此次搜索没有搜索到,直接返回 false ,具体看代码实现:
Code
class Solution {
static constexpr int DIRS[4][2] = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
public:
bool wordPuzzle(vector<vector<char>>& grid, string target) {
int m = grid.size(), n = grid[0].size();
auto dfs = [&](auto&& dfs, int i, int j, int k) -> bool {
if (grid[i][j] != target[k]) { // 当前字符匹配失败
return false;
}
if (k + 1 == target.length()) { // 匹配成功
return true;
}
grid[i][j] = 0; // 标记访问过
for (auto& [dx, dy]: DIRS) {
int x = i + dx, y = j + dy;
// 没有越界并且搜索成功
if (x >= 0 && x < m && y >= 0 && y < n && dfs(dfs, x, y, k + 1)) {
return true;
}
}
// 没有搜到,恢复现场
grid[i][j] = target[k];
return false;
};
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (dfs(dfs, i, j, 0)) {
return true;
}
}
}
return false;
}
};